Making the Worlds Worst MNIST Classifier
Background
Back in 2023 I was working on a capstone project using multimodal flexible diffusion models to build AI agents with internal world models which would (in theory) be able to learn to act in complex environments by learning a generative model of the world around them. While that specific project never panned out, that same idea does form the basis of other more successful agents like Dreamer from DeepMind. As a part of that project as a learning exercise I built what could be described as the world's worst MNIST classifier which used a multimodal diffusion model to learn the joint distribution of handwritten digits and their labels, then used that to classify images by sampling from the conditional distribution of labels given an image.
While this is a very roundabout and inefficient way to build an MNIST classifier, it is a fun exercise to demonstrate an interesting and overlooked feature of diffusion models: they can learn to generate data from conditional distributions without ever being trained on those conditional distributions directly. This might seem somewhat obvious from a stats 101 perspective, afterall the conditional distribution is just a subset of the joint distribution, but in practice it is quite interesting that you can see a model generalize to learning how to label digits from scratch when you never directly train it to do so.
Surprisingly it took quite awhile for this idea to catch on. While the principle of flexible joint diffusion here is based off work I did in 2023, following up on work done earlier in the PLAI lab at UBC doing flexible diffusion for video rollouts, the idea of multimodal flexible diffusion for conditional generation I used for this refined version is based off of the UniCon framework only published in April of 2025.
Theory
While the idea of a "multimodal flexible" sounds like a fancy concept that would be technically difficult to approach, the core principle can be demonstrated with basic probability theory. In fact, it can be summarized in three words: "marginalizing over the prior."
From a statistical perspective, you can imagine the most basic MNIST handwriting classifier as simply sampling from the probability distribution of labels conditioned on the image we are trying to classify:
While this framework works perfectly fine for a simple toy problem like MNIST classification, this direct approach has limitations for more complex domains. For example, in reinforcement learning settings like playing Minecraft, you could in principle train a model to sample from:
However, this behavior cloning approach struggles with compounding errors and lacks the ability to plan or reason about consequences. World models offer an alternative: instead of learning the conditional distribution directly, we learn a generative model of the entire environment and use it to answer conditional queries.
Diffusion Models
For our MNIST classifier, this means training a model on the joint distribution of images and labels:
At first glance this seems unhelpful - after all, we want to classify images, not generate random image-label pairs. But anyone familiar with Bayes' rule knows we're just a simple transformation away from the classifier we want:
The problem is the denominator. Computing (P(image)) requires summing over all possible labels - and in more complex settings, this marginalization becomes intractable.
This is where diffusion models save the day. Diffusion models, as introduced by Ho et al. (2020), learn the score function: the gradient of log-probability with respect to the data being denoised (see Yang Song's excellent blog post for an in-depth explanation of score-based generative modeling):
where is the noisy version of our data at diffusion timestep .
Suppose we train a diffusion model on the joint distribution of (image, label) pairs. We can think of our noisy data as (x_t = (image_t, label_t)). The model learns:
Now here's the key insight. To sample from the conditional distribution , consider its score function with respect to the label:
Since (P(image_t)) doesn't depend on (label_t), it vanishes under differentiation:
This is remarkable: our joint model already knows the conditional score function. The normalization constant disappears because it's constant with respect to the variable we're differentiating.
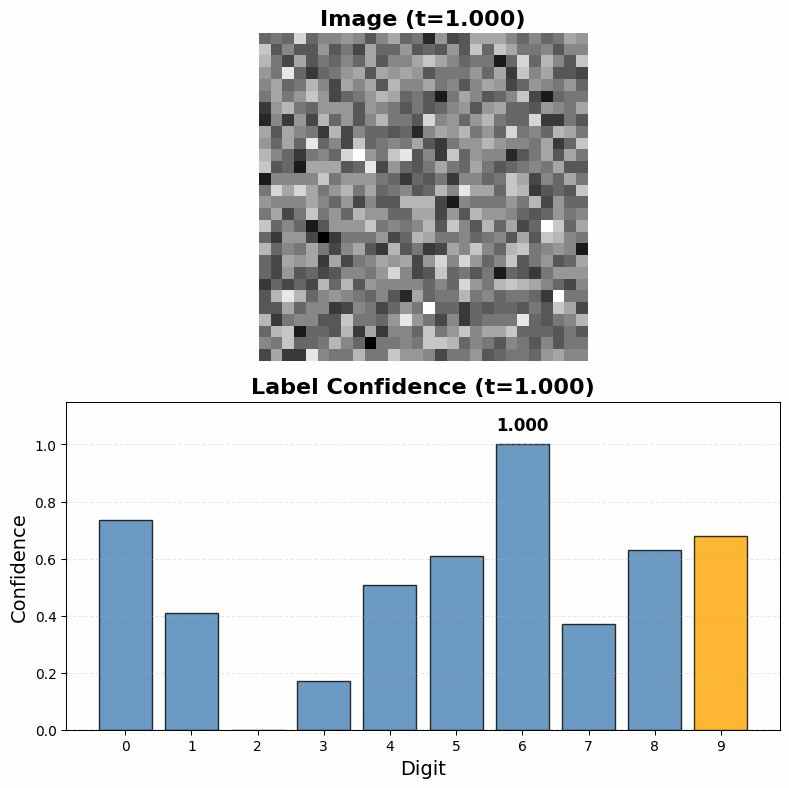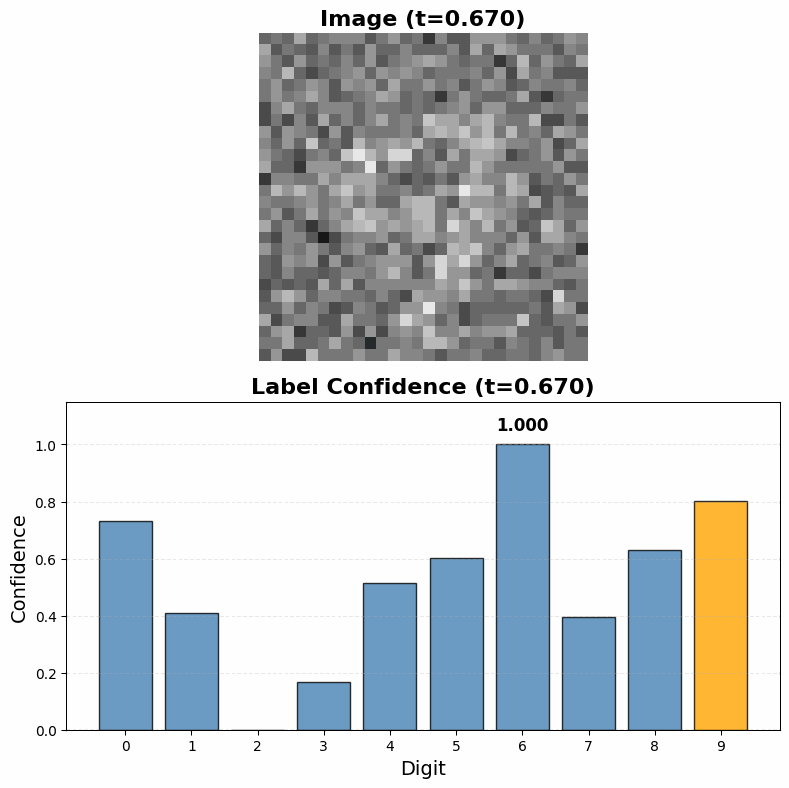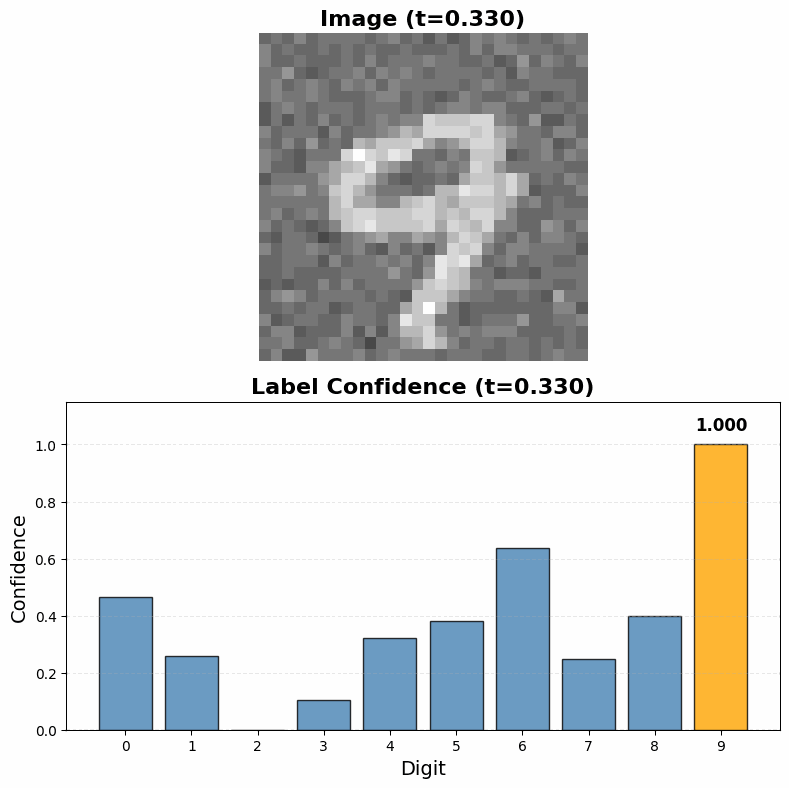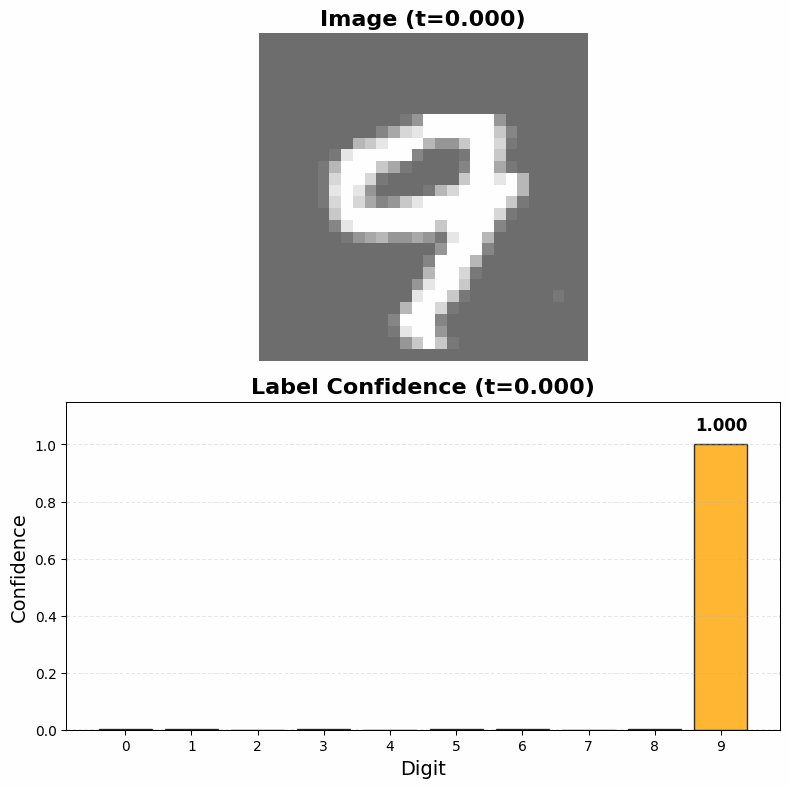
To classify an image, we simply run the diffusion denoising process while holding the image fixed, allowing only the label component to evolve. The model will denoise toward high-probability labels for that specific image—effectively sampling from (P(label \mid image)) without ever computing it explicitly.
Beyond MNIST
While this is all a bit contrived for a task as simple as an MNIST classifier, it really shines when we have to model more complex domains. For example, what if we wanted to model the joint distribution of the game state and actions in a game like Minecraft? We could train a diffusion model on the joint distribution of (game state, action) pairs:
Then we could use the same score function trick to sample from the conditional distribution of actions given a game state:
This exact process is exactly what is used for the backbone of the world model in state of the art agents like Dreamer 4. Of course, in practice a lot more is needed to make a model which is actually useful, and the key part of Dreamer is the ability to use the world model to as a backbone for a further RL training process to give the agent the ability to plan and reason about its actions.
Implementation
Architecture
For this project the diffusion model is based off a standard U-Net style convolutional architecture on the image side, with a simple MLP to handle the label side. The one unusual aspect is that the models are have their middle encodings share information via a cross-attention layer, allowing the image and label modalities to influence each other during the denoising process. This is inspired by the UniCon architecture which works in a similar manner, but has the one downside that the layer sizes have to be matched up for both the image and label branches. This makes the model quite inefficient since the complexity of the label branch is minimal compared to the image branch, but it is a simple way to get the model working.

Time embeddings are added to both branches using sinusoidal positional encodings and a time MLP to inject learned time encodings before the middle bottleneck layers.
At the shared bottleneck layer, the image and label branches cross-attend to each other using standard multi-head attention layers. Then each label is refined using a parameterized fully connected layers to allow for multiple attention layers to be stacked if desired.
Training
The model is trained using a standard flow matching diffusion loss, where the final images and labels are interpolated with Gaussian noise at a random timestep between 0 and 1 and the model is trained produce a velocity field which can be integrated to denoise the data. The one main difference between this and most standard diffusion models is that the loss is computed jointly over both the image and label modalities rather than one or the other. To do this we simply train on the losses of both the image and label denoising at the same time, where the chosen timestep we are denoising from is indepedently sampled for both modalities. This allows the model to learn to denoise both modalities at different rates, which is important as we want the model to implicitly learn both the joint (starting from both distributions fully noised) and the conditional (starting from one modality fully noised and the other clean) distributions.
As an aside, while this training scheme seems quite simple and like it would be the first thing you would try when training a model like this, it infact took awhile to discover this. The earliest versions of the model I trained back in 2023 used a more complex training scheme inspired by "Flexible Diffusion Modeling of Long Videos" from the PLAI lab, which would randomly choose to either sample each modality conditionally, jointly, or unconditionally at each training step. In comparison, this newer method of simply independently sampling the timesteps of each modality taken from UniCon is much simpler and seems to work better in practice.
Results
The resulting model from this training process is able to both successfully classify MNIST digits and generate realistic handwritten digits from labels alone. While it is not a surprise that the model can classify MNIST digits (I'm pretty sure a potato with backpropagation could do that), it is interesting that it is at all able to do so given that it was never directly trained to classift digits. It is remarkable to see that even though the training process gives only partially noised samples of the labels during most training steps and the model is never truly given the task of discovering the correct label for a fully clean image it is still able to generalize to that task at inference time.
Classification

Overall we see the model achieve a classification accuracy of 98% on the MNIST test set after training for 900 epochs, which is quite respectable for such a roundabout method of classification, though a few orders of magnitude more compute than a more conventional method would use. The generated digits from labels are also quite good, with the model able to generate realistic and diverse samples for each digit class.
Image Generation
Of course as a side effect of the model being a generative model of image label pairs, we can reverse the relationship and generate conditional images from labels as well. Below are some samples of generated digits from each label class:

The generated digits are legible and most closely resemble real samples from the MNIST dataset, though some do come out a little bit janky looking. This is expected given that while I did train the model for quite a while for a classification task, I stopped quite early of the model converging on high quality generation since classification was the main goal of the project (and I because I was paying for compute time by the hour).
Of course we can also sample from the model in the same way it was trained, by jointly denoising both an image and label from pure noise. Below are some joint samples from the model:

Interestingly while it does successfully generate some realistic looking samples of digits and labels, the quality of the image generation is noticeably worse than the conditional generation from labels alone. My hypothesis is that because it doesnt have the early "guidance" of a label to help steer the image generation in the early denoising stages, the model gets locked into weird looking shapes early in generation, which it then has no way of recovering on later on. This probably could be improved by training the model for longer but its interesting to see that the model performas the worst on the task it was directly trained for.
Six Seven
One big issue with this model you might notice is that the one hot encoding scheme is quite unnatural to diffuse to. While it is simple enough that the model can easily learn the distribution, it does seem quite inefficient to use a continuous domain method like diffusion on what is effectively a discrete distribution. However this method does give us the upside of allowing us to force the model to generate images out of distribution by manipulating the label embeddings into unnatural states during inference. For example, if instead of simply using the one hot encodings for the labels, we instead used a linear combination of two numbers, like say, six and seven, we could then finally answer the question of what six seven truly is:

Of course we could also expand this to every combination of digits and generate a matrix of what each digit combination looks like:

These results are not anything meaningful as we are generating samples clearly out of distribution. Given that we should have no expectation that the model actually will create a meaningful interpolation between any two classes. It is still fun to see what happens when we try though.
Conclusion
On one hand model sucks as both a practical MNIST classifier as well as a generative model for handwritten digits, but on the other hand one must consider, six seven.
References
-
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. The foundational paper introducing DDPMs for high-quality image synthesis.
-
Lipman, Y., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., & Le, M. (2022). Flow Matching for Generative Modeling. ICLR 2023. Introduces flow matching as an efficient alternative training paradigm for continuous normalizing flows.
-
Song, Y. (2021). Generative Modeling by Estimating Gradients of the Data Distribution. An excellent blog post explaining score-based generative models and their connection to diffusion models.
Multimodal and Flexible Diffusion
-
Li, X., Herrmann, C., Chan, K. C. K., Li, Y., Sun, D., Ma, C., & Yang, M.-H. (2025). UniCon: A Simple Approach to Unifying Diffusion-based Conditional Generation. ICLR 2025. The framework that inspired the independent timestep sampling approach used in this project. Project page
-
Harvey, W., Naderiparizi, S., Masrani, V., Weilbach, C., & Wood, F. (2022). Flexible Diffusion Modeling of Long Videos. NeurIPS 2022. Earlier work from the PLAI lab at UBC on flexible diffusion for video, which inspired my initial approach.
World Models and Reinforcement Learning
- Hafner, D., Yan, W., & Pieter, A. (2025). Training Agents Inside of Scalable World Models (Dreamer 4). The state-of-the-art world model agent that uses diffusion-based world models for RL in Minecraft.